
Ana Marcet y Manuel Perea
ERI-Lectura, Universitat de València, Valencia, España

(cc) Benjamin.
Las imitaciones de logotipos y nombres de productos, empresas o páginas web representan una realidad cotidiana en nuestra sociedad. Por ello, es importante examinar cómo reconocemos logotipos y marcas para evitar ser engañados por productos falsos o webs fraudulentas. En este artículo presentamos dos trabajos recientes en tal sentido, en un ámbito que une la psicología cognitiva y el marketing. En el primero, mostramos la dificultad de identificar un logotipo, muy familiar, entre logotipos falsos. En el segundo, mostramos cómo nuestro sistema perceptivo tiene dificultades para reconocer correctamente las palabras de direcciones web fraudulentas que son visualmente similares a la original (p.ej., www.rnicrosoft.com).
A día de hoy no nos extraña ver imitaciones de productos (p.ej., bolsos o zapatillas de marca, camisetas de fútbol, etc.) a la venta en las calles de nuestras ciudades por mucho menos dinero de su valor real. Muchos consumidores compran productos falsificados, incluso cuando son conscientes de que no son los auténticos. Este hecho ha convertido al comercio de falsificaciones en una industria multimillonaria. Aunque algunos consumidores busquen activamente productos falsificados, entre otras cosas debido a que tienen un precio mucho más bajo que el producto original, otros consumidores desean un producto auténtico. Estos últimos a menudo son engañados y acaban comprando un producto falsificado por no poder diferenciar un logotipo falso de uno real. En este sentido, las empresas luchan para que otros no se aprovechen del éxito de sus productos, protegiéndose con patentes que impiden el registro de otras marcas y logotipos visualmente similares que puedan llevar al engaño. Un ejemplo reciente ocurrió cuando se intentó registrar en España la marca John Lennon, pero no se pudo al existir John Lemon como una marca de cervezas. De manera similar, es fácil encontrarse con webs fraudulentas que se parecen a las originales en nombre, diseño, etc. con el objetivo de obtener datos personales de los usuarios (Moreno-Fernández, Blanco, Garaizar y Matute, 2017).
Las investigaciones sobre cómo reconocemos marcas y logotipos representan un ámbito que está en auge y suponen un punto de unión entre la psicología cognitiva y el marketing (Perea, Jiménez, Talero y López-Cañada, 2015; van Horen y Pieters, 2012). A continuación describimos dos trabajos recientes, uno sobre logotipos y otro sobre nombres de marcas, que ejemplifican la facilidad que pueden tener los imitadores de marcas para hacer creer a los compradores que un producto es original cuando realmente se trata de una copia.
El logotipo de Apple ha sido catalogado como uno de los logotipos más conocidos en el mundo. Por tanto, se podría esperar que las personas pudieran identificar dicho logotipo y diferenciarlo de posibles imitaciones sin demasiadas dificultades. Sin embargo, como mostraron Blake, Nazarian y Castel (2015), las personas tienen dificultades en distinguir el logotipo verdadero de Apple de las imitaciones. En uno de sus experimentos, los participantes habían de identificar el logotipo de Apple entre un conjunto de ocho posibles logotipos con pequeñas modificaciones: forma de la manzana, dirección de la hoja u orientación del logotipo. Menos de la mitad de personas (un 47%) fueron capaces de identificar correctamente el logotipo. Blake y col. (2015) sugirieron que, dada la familiaridad y sencillez del logotipo de Apple, se puede generar una cierta saturación atencional que resulte en una escasa atención a los detalles del logotipo. Estas dificultades en distinguir el logotipo de una marca pueden volverse en nuestra contra, dado que podemos creer falsamente que un producto es original cuando realmente estamos ante una imitación.
Si hablamos de páginas de Internet, es de gran importancia saber a ciencia cierta que el dominio al que estamos accediendo es seguro. Para no caer en el engaño hay que discriminar correctamente si se trata de una página web auténtica o no. Una estrategia que siguen muchas direcciones web fraudulentas es contener palabras con homoglifos por combinación de letras, es decir, pares de letras que se parezcan visualmente a la original (p.ej., rn→m www.sarnsung.com, rnicrosoft.com). Para examinar el papel de los homoglifos en los primeros momentos del acceso al léxico, Marcet y Perea (2017) realizaron dos experimentos con la técnica de presentación enmascarada del estímulo-señal (véase la Figura 1). En sus experimentos, cada palabra-test podía ir precedida brevemente por: 1) una palabra idéntica (documento-DOCUMENTO; presidente-PRESIDENTE); 2) una pseudopapabra que contenía un homoglifo por combinación de letras (docurnento-DOCUMENTO; presiclente-PRESIDENTE); o 3) un control ortográfico en el que se sustituyó la primera de las letras de la combinación (p.ej., rn→sn) (docusnento-DOCUMENTO; presiglente-PRESIDENTE). Si en los primeros momentos de procesamiento los homoglifos se procesan como las letras originales, los tiempos de identificación de las palabras-test serían más rápidos en la condición con homoglifos que en la condición de control. Además, se esperarían tiempos de respuesta similares en las condiciones de homoglifos y de identidad.
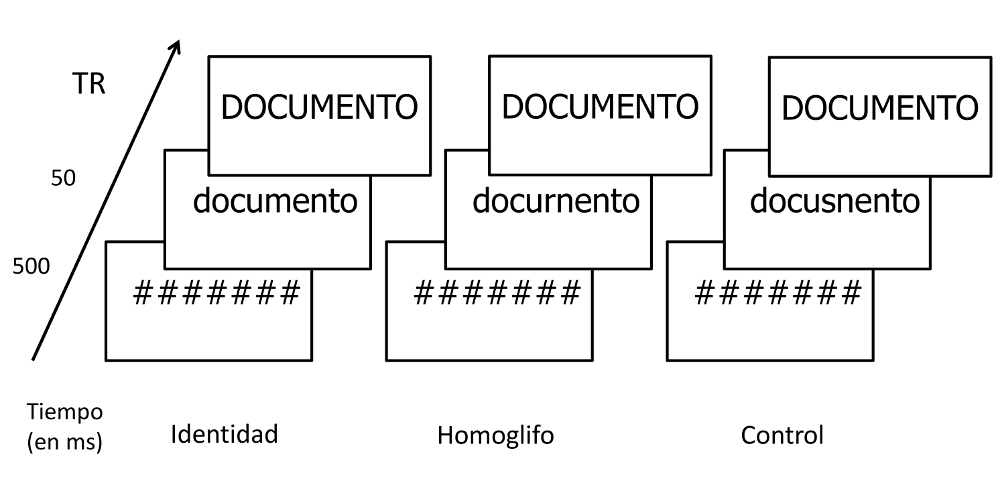
Figura 1.- Ejemplo de ensayo con la técnica de presentación enmascarada del estímulo-señal empleada por Marcet y Perea (2017). La tarea de los participantes era decidir, lo más rápido posible intentando no cometer errores, si el estímulo-test en mayúsculas era palabra o no (es decir, una decisión léxica). Las variables dependientes son el tiempo de reacción (TR) y la precisión.
El primer experimento, realizado con una fuente de letra muy habitual (Tahoma, fuente por defecto en Facebook) confirmó ambas predicciones (véase la Figura 2).
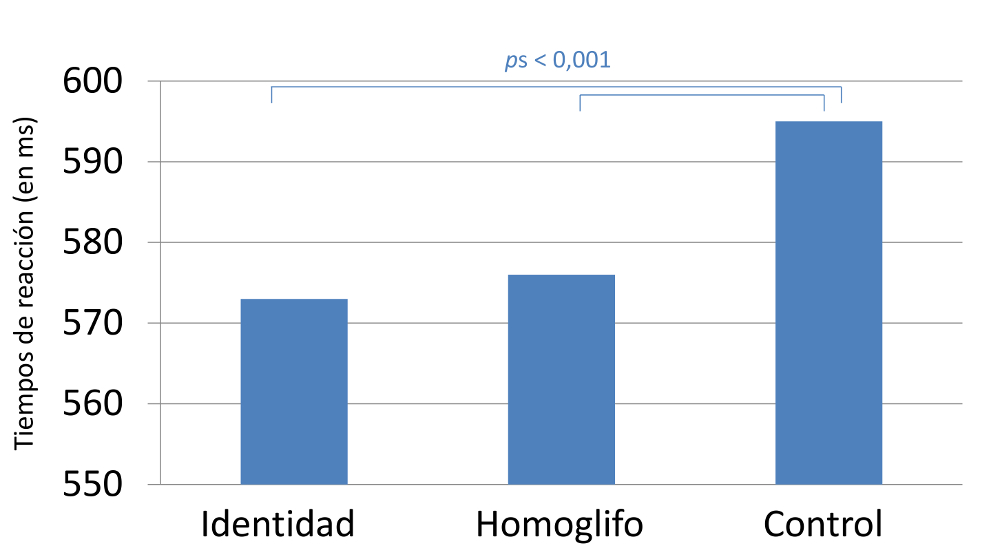
Figura 2.- Tiempos medios de identificación de las palabras-test (en milisegundos) en cada una de las condiciones experimentales del Experimento 1 de Marcet y Perea (2017).
Dichos resultados muestran que los usuarios de Internet deberían ser conscientes del riesgo de ser engañados con nombres de dominios visualmente parecidos a los reales (p.ej., www.sarnsung.com). ¿Cómo podría modificarse la barra de direcciones de los navegadores de internet para minimizar dichos riesgos? Como señalaron Marcet y Perea (2017), un elemento importante para minimizar los efectos de similitud de los homoglifos por combinación de letras es aumentar espaciado entre caracteres. En su segundo experimento emplearon una fuente con un espaciado algo mayor (Calibri, fuente por defecto en MS-Word) y los efectos de similitud visual, si bien seguían existiendo, fueron sensiblemente menores.
En definitiva, la imitación está muy extendida en todo tipo de marcas: diseño de sitios web, publicidad, logotipos, tiendas y productos. Las investigaciones anteriormente descritas y las que puede haber en un futuro sobre cómo se perciben las falsificaciones pueden contribuir a controlar la competencia, preservar la integridad de los productos y determinar qué imitadores están cometiendo fraude, para poder así luchar contra la industria de la falsificación y reforzar las leyes que regulan la protección de las marcas.
Referencias
Blake, A.B., Nazarian, M. y Castel, A.D. (2015). The Apple of the mind’s eye: Everyday attention, metamemory, and reconstructive memory for the Apple logo. Quarterly Journal of Experimental Psychology, 68, 858–865.
Marcet, A. y Perea, M. (2017). Can I order a burger at rnacdonalds.com? Visual similarity effects of multi-letter combinations at the early stages of word recognition. Journal of Experimental Psychology: Learning, Memory, & Cognition. doi:10.1037/xlm0000477
Moreno-Fernández, M.M., Blanco, F., Garaizar, P. y Matute, H. (2017). Fishing for phishers. Improving Internet users’ sensitivity to visual deception cues to prevent electronic fraud. Computers in Human Behavior, 69, 421–436,
Perea, M., Jiménez, M., Talero, F. y López-Cañada, S. (2015). Letter-case information and the identification of brand names. British Journal of Psychology, 106, 162–173.
Van Horen, F. y Pieters, R. (2012). When high-similarity copycats lose and moderate-similarity copycats gain: The impact of comparative evaluation. Journal of Marketing Research, 49, 83–91.
Manuscrito recibido el 13 de noviembre de 2017.
Aceptado el 12 de diciembre de 2017.
