
Rubén San Segundo
Grupo de Tecnología del Habla, Dpt. de Ingeniería Electrónica, E.T.S.I. Telecomunicación, Universidad Politécnica de Madrid, España
 Los últimos avances tecnológicos han permitido que se desarrollen sistemas de traducción automática de voz a Lengua de Signos con la calidad suficiente como para permitir traducir las expresiones o explicaciones que una persona oyente quiere transmitir a una persona sorda en un dominio de aplicación concreto. Estos sistemas permitirán la comunicación entre personas oyentes y sordas en las situaciones en las que no sea posible disponer de intérpretes humanos.
Los últimos avances tecnológicos han permitido que se desarrollen sistemas de traducción automática de voz a Lengua de Signos con la calidad suficiente como para permitir traducir las expresiones o explicaciones que una persona oyente quiere transmitir a una persona sorda en un dominio de aplicación concreto. Estos sistemas permitirán la comunicación entre personas oyentes y sordas en las situaciones en las que no sea posible disponer de intérpretes humanos.
La traducción automática ha sido un campo de investigación de gran interés a nivel internacional. En Estados Unidos este interés se ha centrado últimamente en la traducción de la lengua árabe al inglés como consecuencia de los atentados del 11-S. En la Comunidad Europea hay una gran cantidad de lenguas oficiales y, por tanto, mucho trabajo de traducción de los documentos oficiales.
Hasta la fecha, los mejores sistemas de traducción están basados en modelos estadísticos que intentan analizar la probabilidad de que la traducción de las palabras de la lengua de destino (tomando en consideración las de la lengua de origen) sean las más adecuadas (Och y Ney, 2002). Para la estimación de estas probabilidades se necesitan muchas frases ya traducidas (corpus paralelos). Para conseguirlas, se utilizan técnicas de traducción estadística, entre las que destacan las técnicas basadas en ejemplos (traducción por analogía; Sumita y col, 2003), traductores basados en estructuras gramaticales de las lenguas (Casacuberta y Vidal, 2004) y otras soluciones.
Los importantes progresos conseguidos en los procesos de traducción de habla se deben principalmente a la aparición de medidas de error automáticas (Papineni, Roukos, Ward, y Zhu, 2004). Hasta ahora sólo se podía saber si una traducción era correcta pidiendo a un experto traductor que la valorase, una labor muy lenta. Otro factor que ha agilizado los procesos de traducción del habla ha sido la mejora de la eficiencia de los algoritmos de entrenamiento para el cálculo de las probabilidades de traducción (Och y Ney, 2003), así como el desarrollo de modelos dependientes del contexto (Koehn, Och y Marcu, 2003), en los que no sólo se tiene en cuenta la palabra a traducir sino el lugar que ocupan en la frase, así como las palabras adyacentes.
En los últimos años ha aumentado el interés de varios grupos de investigación por la traducción automática de voz a lengua de signos, desarrollándose varios prototipos: basados en ejemplos (Morrissey y Way, 2005), en reglas de traducción escritas por un experto (San-Segundo, 2008), en frases completas ya traducidas anteriormente (Cox y col., 2002), o en soluciones estadísticas (Bungeroth y Ney, 2004).
Basándonos en datos del INE y del MEC (CNSE, 2003), en España, el 47% de las personas sordas o con discapacidad auditiva temprana mayores de 10 años no tienen estudios o son analfabetas. La realidad nos muestra que, de este colectivo, hasta un 92% padece analfabetismo funcional: tienen serias dificultades para comprender textos y expresarse correctamente por escrito. Así, sólo entre un 1% y un 3% de las personas sordas en España han superado estudios universitarios, niveles muy inferiores al del conjunto de la población española.
Esto tiene diversas consecuencias en la calidad de vida de las personas sordas. La que nos interesa destacar en este artículo está relacionada con el acceso de las personas sordas a la información. En este sentido, la Lengua de Signos Española (LSE), una lengua natural en las personas sordas que se estructura en los mismos niveles lingüísticos y cumple las mismas funciones que cualquier lengua oral, puede contribuir de forma efectiva a su mejor acceso a la información, la supresión de las barreras de comunicación y la igualdad de oportunidades.
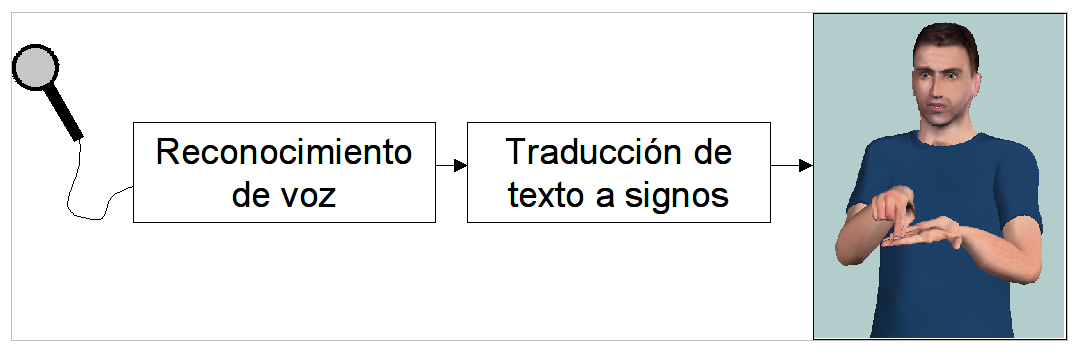
Figura 1.- Diagrama de las fases en las que se desarrolla el sistema de traducción de voz a LSE.
La Universidad Politécnica de Madrid (UPM) y la Confederación Nacional de Sordos Españoles (Fundación CNSE) han colaborado durante los últimos años para desarrollar el primer sistema de traducción de voz a Lengua de Signos Española (LSE). En la página web https://www.traduccionvozlse.es se pueden consultar algunos vídeos de demostración del sistema desarrollado. Este sistema es capaz de traducir, por ejemplo, las expresiones pronunciadas por los funcionarios de la administración pública cuando atienden a una persona sorda que desea renovar el permiso de conducir o el Documento Nacional de Identidad (DNI). El sistema realiza el proceso de traducción en tres pasos (véase la Figura 1). En el primero, un reconocedor de voz se encarga de traducir la voz a una secuencia de palabras. En segundo lugar, un módulo de traducción automática traduce la secuencia de palabras a una secuencia de signos. El módulo de traducción combina dos estrategias de traducción: una basada en ejemplos y otra basada en reglas de traducción escritas por un experto. Finalmente, dado que la Lengua de Signos es visual, es necesario incorporar un módulo de animación de los signos basado en un agente animado virtual en 3D. Este agente animado ha sido desarrollado en el proyecto eSIGN (https://www.sign-lang.uni-hamburg.de/eSIGN/) y está disponible para su empleo en investigación.

Figura 2.- Interfaz del programa desarrollado y ejemplo de uso del sistema.
Un aspecto muy importante en la evaluación de la tecnología desarrollada tiene que ver con su empleo con usuarios finales. En este caso, el sistema desarrollado ha sido evaluado en la Jefatura Provincial de Tráfico de Toledo con funcionarios oyentes y personas sordas, obteniendo unos resultados muy prometedores (veáse Figura 2). Estos resultados animan a continuar trabajando en el desarrollo de sistemas similares que acerquen la administración pública a las personas sordas.
Agradecimientos
Estos trabajos han sido financiados por el Plan Avanza y la Fundación ONCE.
Referencias
Bungeroth, J., y Ney, H. (2004). Statistical sign language translation. En: Streiter, O. y Vettori, C. (Eds). Workshop on representation and processing of sign languages. Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC), pp. 105-108.
Casacuberta, F., y Vidal, E. (2004). Machine translation with inferred stochastic finite-state transducers. Computer Linguistics, 30, 205-225.
Cox, S. L., Lincoln, M., Tryggvason, J., Nakisa, M., Wells, M., Mand, T., y Abbott, S. (2002). TESSA: A system to aid communication with deaf people. Proceedings of the Fifth International ACM Conference on Assistive Technologies, Edinburgh, Scotland, pp. 205-212.
Koehn, P., Och, F. J. y Marcu, D. (2003). Statistical phrase-based translation. Proceedings of the Human Language Technology Conference (HLT-NAACL), Edmonton, Canada, pp. 127-133.
Morrissey, S. y Way. A. (2005). An example-based approach to translating sign language. Workshop on Example-Based Machine Translation (MT X-05), Phuket, Thailand, pp. 109-116.
Och, J. y Ney., H. (2002). Discriminative training and maximum entropy models for statistical machine translation. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, pp. 295-302.
Och J., y Ney, H. (2003). A systematic comparison of various alignment models. Computational Linguistics, 29, 19-51.
Papineni, K., Roukos, S., Ward, T. y Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, pp. 311-318.
San-Segundo, R., Barra, R., Córdoba, R., D’Haro, L. F., Fernández, F., Ferreiros, J., Lucas, J. M., Macías-Guarasa, J., Montero, J. M., Pardo, J. M. (2008). Speech to Sign Language translation system for Spanish. Speech Communication, 50, 1009-1020.
Sumita, E., Akiba, Y., Doi, T., Finch, A., Imamura, K., Paul, M., Shimohata, M., Watanabe. T. (2003). A corpus-centered approach to spoken language translation. Proceedings of the Conference of the Association for Computational Linguistics (ACL), Hungary, pp. 171-174.
Manuscrito recibido el 13 de septiembre de 2009.
Aceptado el 8 de octubre de 2009.
